
مقدمه ای بر چیستی، چرایی و چگونگی محاسبات حافظه توزیع شده
در آخرین پست در این مجموعه وبلاگ مدلسازی ترکیبی، ما اصول اساسی پشت محاسبات حافظه مشترک را مورد بحث قرار دادیم – چیست، چرا از آن استفاده می کنیم، و چگونه نرم افزار COMSOL از آن در محاسبات خود استفاده می کند. امروز، ما قصد داریم تا بلوک سازنده دیگر محاسبات موازی ترکیبی را مورد بحث قرار دهیم: محاسبات حافظه توزیع شده .
فرآیندها و خوشه ها
با یادآوری آنچه در آخرین پست وبلاگ آموختیم ، اکنون می دانیم که محاسبات حافظه مشترک استفاده از رشته ها برای تقسیم کار در یک برنامه به چندین واحد کاری کوچکتر است که می توانند به صورت موازی در یک گره اجرا شوند. این رشتهها دسترسی به بخش خاصی از حافظه را به اشتراک میگذارند – از این رو به آن محاسبات حافظه مشترک میگویند . در مقابل، موازیسازی در محاسبات حافظه توزیعشده از طریق چندین فرآیند انجام میشود که رشتههای متعددی را اجرا میکنند، که هر کدام دارای یک فضای خصوصی از حافظه هستند که سایر فرآیندها نمیتوانند به آن دسترسی داشته باشند. همه این فرآیندها که در چندین کامپیوتر، پردازنده و/یا چندین هسته توزیع شده اند، بخش های کوچکی هستند که با هم یک برنامه موازی را در رویکرد حافظه توزیع شده ایجاد می کنند .
به بیان ساده، حافظه دیگر به اشتراک گذاشته نمی شود، توزیع می شود (نمودار را در اولین پست وبلاگ ما در این مجموعه بررسی کنید.)
برای درک اینکه چرا محاسبات توزیع شده به این روش توسعه یافته است، باید مفهوم اساسی محاسبات خوشه ای را در نظر بگیریم . حافظه و قدرت محاسباتی یک کامپیوتر تنها توسط منابع آن محدود شده است. به منظور دستیابی به عملکرد بیشتر و افزایش مقدار حافظه در دسترس، دانشمندان شروع به اتصال چندین کامپیوتر به همدیگر در چیزی کردند که به آن خوشه کامپیوتری میگویند .
تقسیم مشکل
ایده توزیع فیزیکی فرآیندها در یک خوشه کامپیوتری منجر به سطح جدیدی از پیچیدگی هنگام موازی سازی مسائل می شود. هر مشکلی باید به قطعات تقسیم شود – داده ها باید تقسیم شوند و وظایف مربوطه باید توزیع شوند. یک مسئله نوع ماتریسی را در نظر بگیرید، جایی که عملیات روی یک آرایه عظیم انجام می شود. این آرایه را میتوان به بلوکهایی تقسیم کرد (شاید منفصل، شاید همپوشانی داشته باشند) و هر فرآیند بلوک خصوصی خود را مدیریت میکند. البته، عملیات و دادههای موجود در هر بلوک ممکن است با عملیات و دادههای موجود در بلوکهای دیگر همراه شود، که این امر لزوم معرفی مکانیزم ارتباطی بین فرآیندها را ضروری میسازد.
برای این منظور، داده ها یا اطلاعات مورد نیاز سایر فرآیندها به صورت تکه هایی جمع آوری می شوند که سپس با ارسال پیام بین فرآیندها مبادله می شوند. این رویکرد ، ارسال پیام نامیده می شود و پیام ها را می توان به صورت جهانی (همه به همه، همه به یک، یک به همه) یا نقطه به نقطه (یک فرآیند ارسال، یک فرآیند دریافت) مبادله کرد. بسته به کوپلینگ های مشکل کلی، ممکن است ارتباطات زیادی لازم باشد.
هدف این است که داده ها و عملیات را تا حد امکان محلی نگه دارید تا حجم ارتباطات را تا حد امکان پایین نگه دارید.
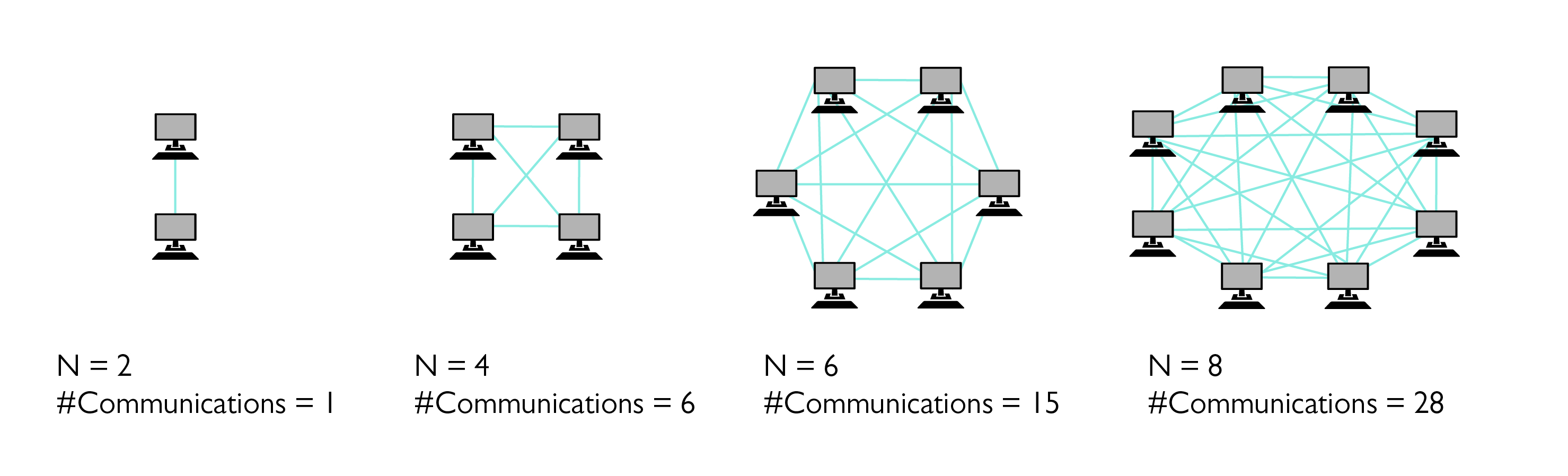
تعداد پیام هایی که باید به صورت همه به همه ارسال شوند را می توان با یک نمودار کامل توصیف کرد . افزایش با توجه به تعداد گره های محاسباتی استفاده شده درجه دوم است.
افزایش سرعت محاسبات یا حل مسائل بزرگتر
دانشمندی که روی یک خوشه کامپیوتری کار می کند می تواند از منابع اضافی به دو روش زیر بهره مند شود.
اول، با حافظه بیشتر و قدرت محاسباتی بیشتر در دسترس، او می تواند اندازه مسئله را افزایش دهد و بدین وسیله مشکلات بزرگتر را در همان زمان از طریق افزودن فرآیندهای اضافی و حفظ بار کاری در هر فرآیند (یعنی اندازه زیرمشکل و تعداد عملیات) حل کند. در همان سطح به این می گویند پوسته پوسته شدن ضعیف .
متناوبا، او می تواند اندازه کلی مشکل را حفظ کند و مسائل فرعی کوچکتر را در تعداد بیشتری از فرآیندها توزیع کند. سپس هر فرآیندی باید با حجم کاری کمتری برخورد کند و میتواند کارهای خود را بسیار سریعتر به پایان برساند. در حالت بهینه، کاهش زمان محاسبات برای مشکل اندازه ثابت توزیع شده روی فرآیندهای P ، P خواهد بود . به جای یک شبیه سازی در هر واحد زمانی (یک ساعت، یک روز و غیره)، شبیه سازی P را می توان در واحد زمانی اجرا کرد. این رویکرد به عنوان مقیاس بندی قوی شناخته می شود .
به طور خلاصه، محاسبات حافظه توزیع شده می تواند به شما در حل مسائل بزرگتر در مدت زمان مشابه کمک کند یا به شما در حل مسائل با اندازه ثابت در مدت زمان کوتاهتر کمک کند.
ارتباط مورد نیاز
بیایید اکنون نگاهی دقیق تر به ارسال پیام بیندازیم. چگونه فرآیندها می دانند که بخش های دیگر برنامه ها چه کاری انجام می دهند؟ همانطور که از بالا می دانیم، فرآیندها به صراحت باید اطلاعات و متغیرهای مورد نیاز خود یا سایر پردازنده ها را ارسال و دریافت کنند. این، به نوبه خود، اشکالاتی را به همراه دارد، به ویژه در مورد زمان ارسال پیام ها از طریق شبکه.
به عنوان مثال، میتوانیم تشبیه اتاق کنفرانس را که در پست وبلاگ حافظه مشترک مورد بحث قرار گرفت، به یاد بیاوریم، جایی که کار مشترک در اطراف یک میز انجام میشد و تمام اطلاعات به صورت رایگان برای همه افراد نشسته در آن میز برای دسترسی و کار کردن، حتی به صورت موازی، در دسترس قرار میگرفت. فرض کنید این بار اتاق کنفرانس و میز آن جای خود را به دفاتر انفرادی داده اند، جایی که کارمندان می نشینند و در اوراقی که پیش رو دارند تغییراتی ایجاد می کنند.
در این سناریو، یکی از کارمندان، بیایید او را آلیس صدا کنیم، تغییری در گزارش A ایجاد میکند و میخواهد این تغییرات را به همکارش باب هشدار داده و به او منتقل کند. او اکنون باید کاری را که انجام می دهد متوقف کند، از دفترش خارج شود، به دفتر باب برود، اطلاعات جدید را تحویل دهد و سپس قبل از ادامه کار به میزش برگردد. این کار بسیار دشوارتر از کشیدن یک ورق کاغذ روی میز در اتاق کنفرانس است. بدترین حالت در این سناریو این است که آلیس زمان بیشتری را صرف هشدار دادن به همکارانش در مورد تغییرات خود می کند تا اینکه واقعاً تغییراتی ایجاد کند .
مرحله ارتباط در نسخه جدید قیاس ما می تواند یک گلوگاه باشد و پیشرفت کلی کار را کند کند. اگر بخواهیم میزان ارتباطی را که باید انجام شود کاهش دهیم (یا سرعت ارتباط را افزایش دهیم، شاید با نصب تلفن در دفاتر، یا استفاده از یک نوع شبکه حتی سریعتر)، میتوانیم زمان کمتری را صرف انتظار برای ارسال پیام کنیم و بیشتر زمان محاسبه شبیه سازی های عددی ما در محاسبات حافظه توزیع شده، گلوگاه معمولاً فناوری است که داده های الکترونیکی را به یکدیگر منتقل می کند، سیم های بین گره ها، اگر بخواهید. استاندارد فعلی صنعت برای ارائه توان عملیاتی بالا و تأخیر کم، Infiniband است که اجازه می دهد پیام ها بسیار سریعتر از اترنت انجام شود.
چرا از حافظه توزیع شده استفاده کنیم؟
محاسبات حافظه توزیع شده دارای چندین مزیت است. یکی از دلایلی که باعث می شود از حافظه توزیع شده استفاده کنید همان چیزی است که در مورد حافظه مشترک وجود دارد. هنگام اضافه کردن توان محاسباتی بیشتر، چه به صورت هستهها، سوکتها یا گرههای اضافی در یک خوشه، میتوانیم فرآیندهای بیشتر و بیشتری را شروع کنیم و از منابع اضافه شده بهره ببریم. ما می توانیم از توان محاسباتی به دست آمده برای دریافت سریعتر نتایج شبیه سازی استفاده کنیم.
با رویکرد حافظه توزیع شده، ما همچنین این مزیت را داریم که با هر گره محاسباتی اضافه شده به یک خوشه، حافظه بیشتری در دسترس داریم. ما دیگر محدود به مقدار حافظه ای نیستیم که برد اصلی ما به ما اجازه می دهد تا در آن بسازیم و در تئوری می توانیم مدل های بزرگ دلخواه را محاسبه کنیم. در اکثر موارد، مقیاس پذیری محاسبات حافظه توزیع شده از محاسبات حافظه مشترک فراتر می رود، یعنی سرعت افزایش در تعداد بسیار بیشتری از فرآیندها (در مقایسه با تعداد رشته های استفاده شده) اشباع می شود.
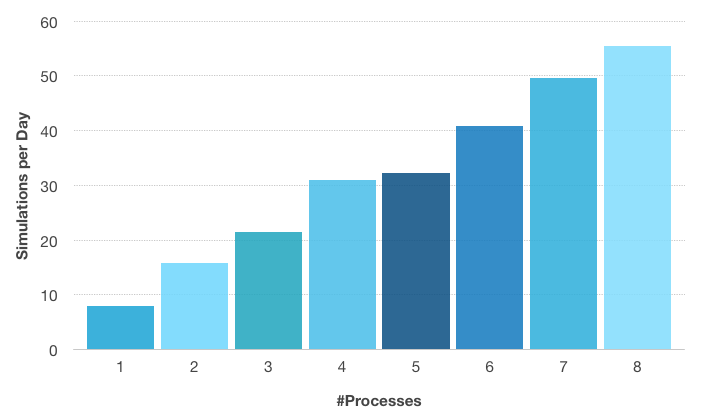
تعداد شبیهسازیها در روز با توجه به تعداد فرآیندهای مورد استفاده برای مدل صدا خفه کن سوراخدار که در زیر نشان داده شده است. یک اترنت 1 گیگابایت بر ثانیه به عنوان شبکه ارتباطی استفاده شد. چهار فرآیند اول بر روی یک گره محاسباتی اجرا میشوند و پس از آن شبکه اترنت مورد استفاده قرار میگیرد. تفاوت اندک در شبیه سازی در روز بین 4 و 5 فرآیند، تأثیر یک شبکه ارتباطی کند را حتی برای یک مشکل پارامتریک نشان می دهد. گره های محاسباتی مورد استفاده مجهز به Intel® Xeon® E5-2609 و 64 گیگابایت DDR3 @1600 مگاهرتز هستند.
با این حال، ما باید از محدودیت ها نیز آگاه باشیم. همانطور که در مورد حافظه مشترک، مشکلاتی وجود دارد که برای محاسبات با رویکرد حافظه توزیع شده مناسب هستند، در حالی که برخی دیگر مناسب نیستند. این بار، ما همچنین باید به میزان ارتباط مورد نیاز برای حل مشکل نگاه کنیم، نه تنها اگر به راحتی موازی شود.
به عنوان مثال، یک مسئله وابسته به زمان را در نظر بگیرید که در آن مقدار زیادی از ذرات به گونهای برهمکنش میکنند که پس از هر مرحله، همه ذرات باید اطلاعات مربوط به هر ذره دیگر را داشته باشند. با فرض اینکه هر یک از ذرات با فرآیند خاص خود محاسبه می شوند، میزان ارتباطات در چنین مثالی را می توان با نمودارهای کاملاً متصل (نشان داده شده در بالا) توصیف کرد و تعداد پیام ها در هر تکرار با تعداد ذرات و فرآیندها به سرعت افزایش می یابد. افزایش دادن. در مقابل، یک جاروی پارامتریک، که در آن مقادیر پارامتریک را می توان مستقل از یکدیگر محاسبه کرد، تقریباً به هیچ ارتباطی نیاز ندارد و از تنگنای ارتباطی رنج نخواهد برد.
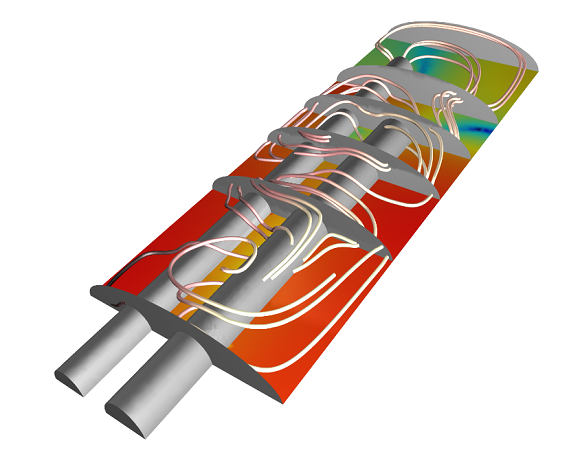
مدلی که برای آن افزایش سرعت به دست آمد. این یک مدل پارامتری کوچک (750000 درجه آزادی) با استفاده از حل کننده مستقیم PARDISO است. این مدل در گالری مدل موجود است .
چگونه COMSOL از محاسبات حافظه توزیع شده استفاده می کند
کاربرانی که به مجوز شبکه شناور (FNL) دسترسی دارند این امکان را دارند که از عملکرد توزیع شده نرم افزار COMSOL بر روی ماشین های تک با چندین هسته، روی یک خوشه یا حتی در فضای ابری استفاده کنند. حلکنندههای نرمافزار COMSOL را میتوان در حالت توزیع شده بدون پیکربندی بیشتر استفاده کرد. از این رو، میتوانید شبیهسازیهای بزرگتر را در همان زمان انجام دهید یا به شبیهسازی با اندازه ثابت خود سرعت دهید. در هر صورت، COMSOL Multiphysics به شما کمک می کند تا بهره وری خود را افزایش دهید.
عملکرد توزیع شده نیز بسیار مفید است اگر شما در حال محاسبه جاروب پارامتری هستید. در این حالت، میتوانید بهطور خودکار اجراهای مرتبط با مقادیر پارامترهای مختلف را در بین فرآیندهایی که COMSOL Multiphysics را با آن شروع میکنید، توزیع کنید. از آنجایی که اجراهای مختلف در چنین جابجایی را می توان مستقل از یکدیگر محاسبه کرد، به این مسئله “مشکل موازی شرم آور” می گویند. سرعت بالا، با یک شبکه اتصال خوب، تقریباً به اندازه تعداد فرآیندها است.
برای دستورالعمل دقیق در مورد نحوه تنظیم کار محاسباتی خود برای محاسبات حافظه توزیع شده، ما کتابچه راهنمای مرجع COMSOL را توصیه می کنیم، که در آن چندین مثال در مورد نحوه راه اندازی COMSOL در حالت توزیع شده فهرست می کنیم . همچنین می توانید برای جزئیات در مورد نحوه ارسال کارهای محاسباتی به راهنمای کاربر خوشه HPC خود مراجعه کنید .
در ادامه این مجموعه وبلاگ ، مفهوم مدلسازی ترکیبی را عمیقتر خواهیم کرد – به زودی دوباره بررسی کنید!
- لینک دانلود به صورت پارت های 1 گیگابایتی در فایل های ZIP ارائه شده است.
- در صورتی که به هر دلیل موفق به دانلود فایل مورد نظر نشدید به ما اطلاع دهید.
برای مشاهده لینک دانلود لطفا وارد حساب کاربری خود شوید!
وارد شوید
دیدگاهتان را بنویسید